
Scalar Value and Built-In Functions
Throughout my career, it has become my strong opinion that the majority of performance problems are self-inflicted due to database design or coding that is less than optimal. This series will address common coding malpractice and the ways to mitigate them.
I once heard that there are 3 types of developers in the IT world; application developers, database developers, and the hybrid of the two. A successful hybrid between database developers and application developers is rare as usually, the two components require different ways of thinking. Application development is object-oriented with the use of methods and functions. Database development is primarily set based.
Many application developers will employ object-oriented coding practices in their environments, and use the same techniques T-SQL.
Scalar Valued Functions as part of the Select clause
The first concept that I will focus on is Scalar Valued Functions. Scalar Valued Functions are “typical” functions that accept a value or set of values and return a value. This sounds fantastic, right? Reuse code to get my information. If your goal is to reuse code, then you can be successful using scalar-valued functions. If your goal is to allow your application and database to scale and grow with minimal performance degradation, then you may want to avoid scalar-valued functions.
Create and use the Function
Let’s look at the AdventureWorks2012 example below. We’ve created a function that returns the order quantity for a sales order ID as shown below.
use AdventureWorks2012
go
if object_id('dbo.ufnSalesOrderQuantity') is not null
drop function dbo.ufnSalesOrderQuantity
go
create function dbo.ufnSalesOrderQuantity
(
@SalesOrderID int
)
Returns smallint
BEGIN
Declare @OrderQty smallint
select @OrderQty = OrderQty
from Sales.SalesOrderDetailEnlarged
where SalesOrderID = @SalesOrderID
return @OrderQty
END
Go
Now that we’ve got the function, how do we use it? See the screenshot below. We simply call the function. What’s great about this? We can change the code in the function and we won’t have to change code anywhere else. Less management, but what is the tradeoff?
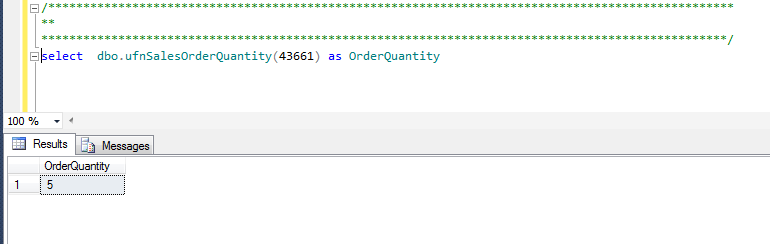
Use the function within a select statement.
Now we will use the function within a select statement. We don’t have to include SalesOrderDetailEnlarged in the query as we already reference it.
print ' /********************************************************************* ** BEGIN Function *********************************************************************/' set statistics io on set statistics time on select top 100000 s.OrderDate, s.SalesOrderNumber, s.PurchaseOrderNumber, s.SalesOrderID, dbo.ufnSalesOrderQuantity(s.SalesOrderID) as OrderQuantity from Sales.SalesOrderHeaderEnlarged s Where TerritoryID = 6 set statistics time off set statistics io off print ' /********************************************************************* ** END Function *********************************************************************/'
I’ve even included the execution plan below. Index SEEK. Just what we want, right?

Notice that we have included our statistics to show how many read and writes we have against the database as well as the time taken. ONLY 628 reads against the database. Fantastic! Let’s look at the same query doing the traditional join.
/********************************************************************* ** BEGIN Function *********************************************************************/ (100000 row(s) affected) Table 'SalesOrderHeaderEnlarged'. Scan count 1, logical reads 628, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 23904 ms, elapsed time = 23934 ms. /********************************************************************* ** END Function *********************************************************************/
Traditional Join
Now we will query the same results, but querying the SalesOrderDetailEnlarged table directly. So much work.
print ' /********************************************************************* ** BEGIN Query *********************************************************************/' set statistics io on set statistics time on select top 100000 s.OrderDate, s.SalesOrderNumber, s.PurchaseOrderNumber, d.OrderQty from Sales.SalesOrderHeaderEnlarged s inner join sales.SalesOrderDetailEnlarged d on d.SalesOrderID = s.SalesOrderID Where TerritoryID = 6 set statistics io off set statistics time off print ' /************************************************************************** ** END Query *************************************************************************/'
Let’s take a look at the execution plan. 77% of the cost is from a clustered index scan, this can’t be what I want.

Let’s now review the IO and time statistics for this query. So many more reads, the function must be the way to go, right?
/********************************************************************* ** BEGIN Query *********************************************************************/ (100000 row(s) affected) Table 'SalesOrderDetailEnlarged'. Scan count 1, logical reads 6093, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeaderEnlarged'. Scan count 1, logical reads 106, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. (1 row(s) affected) SQL Server Execution Times: CPU time = 281 ms, elapsed time = 957 ms. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. /********************************************************************* ** END Query *********************************************************************/
Comparing the results
Did you notice the difference between the two sets of statistics? The statement calling the function has 10% of the reads of the traditional query and the execution plan is seek on only one index, or so it appears. There is one other glaring difference. Notice the CPU Time and Elapsed Time for both. For the call with the function, the CPU time is 23904 milliseconds and a total elapsed time of 23934 milliseconds. For the traditional call, CPU time is 281 milliseconds with a TOTAL elapsed time of 957 milliseconds. How can this be? The execution plan for the statement with the function call is much simpler and there are fewer reads. Could there be more?
The problem here is that the execution of the function is not part of the IO statistics or the execution plan. The results are misleading. In this case, the best way to review the actual work is through either a server-side trace or extended events. I’ve taken the liberty of recording the results using a server-side trace and putting the results to a table to analyze.
Below you will see the results show 100,000 results for this query call. Notice how the query was a “top 100000”. This function is being called 100,000 times, once for each result!
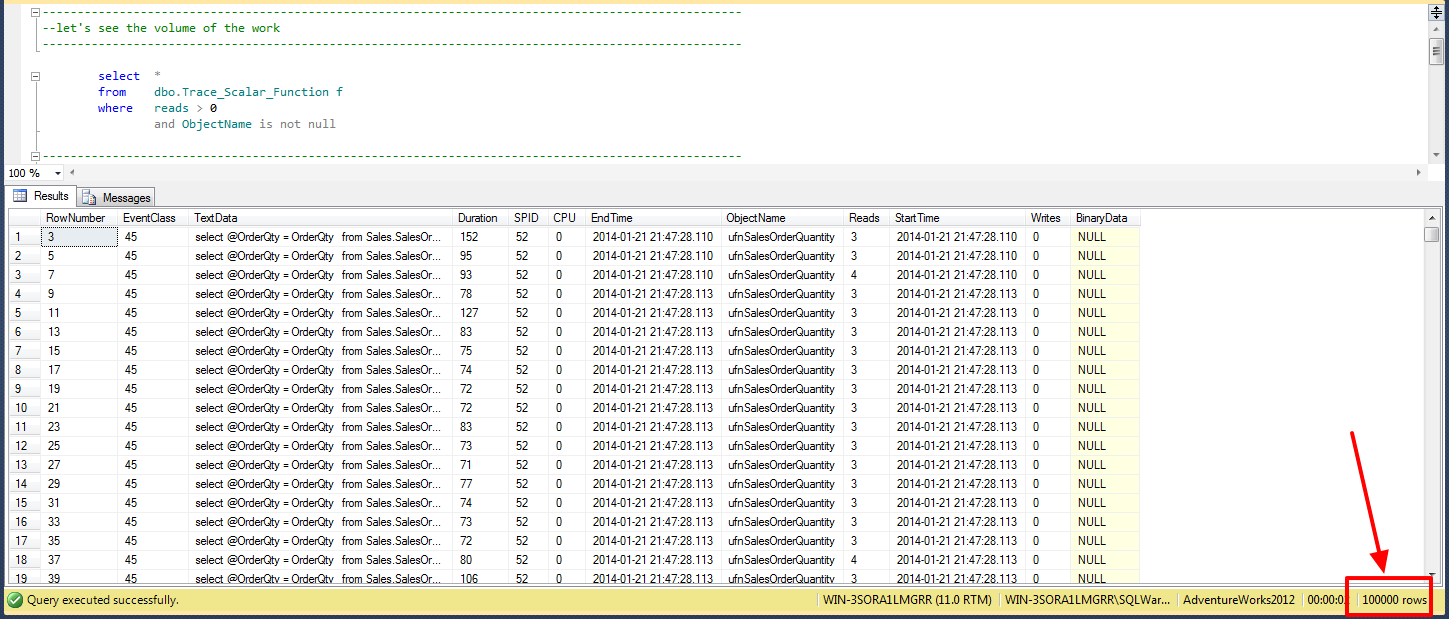
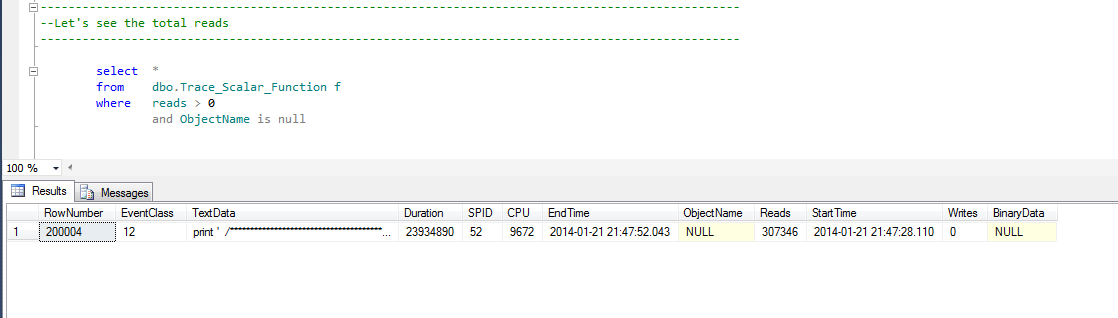
Now let’s take a look at the total cost of the query. 307346 reads. The duration, in this case, was also 23 seconds(I ran the query multiple times).
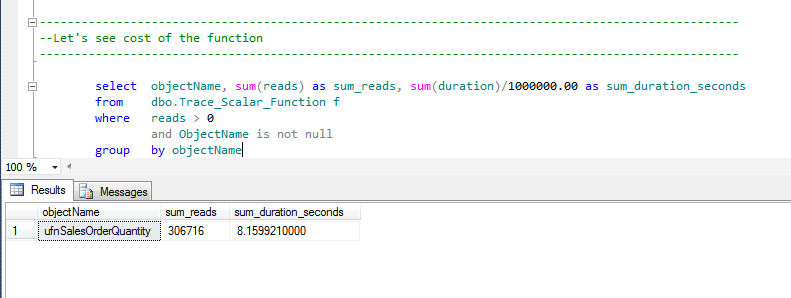
How much of this cost came from the function? 306716 reads came from the function.
Conclusion
Scalar Value Functions are a great way to reuse code, but as we can see here, there are hidden catastrophes caused when using scalar-valued functions on larger data sets. This forces SQL Server to treat each record individually(aka row-by-row processing). We may have more code to maintain by not using the function, but a little work for organizing a release will save migraines when analyzing performance.
Up next: The cost of the union…
Great job Bill, I am looking forward to part 2!
In Oracle the you can use a with clause to force the database to create a temporary table, then join the temporary table to the main part of the query. It looks like SQL Server has something similar. If you move scalar functions into a with clause that can help. Ideally a with clause has a relatively low cardinality compared with the rest of the data.
Good article though.
Mr. Byrd,
Functions and temp tables are not one in the same. SQL Server has temporary tables as well that we can make proper use of. Good post idea!
The with clause in SQL creates a CTE. Generally poor for performance as well.
Please. More. Now.