The State of the Union
After reading part 1 of the series, I hope that you have questioned the use of Scalar Valued Functions. Now, let’s pose some more questions. In this section, we are going to review the Union operator benefits and costs.
The Distinct State of the Union
As microsoft puts it, a Union combines the results of two or more queries into a single result set that includes all the rows that belong to all queries in the union. The UNION operation is different from using joins that combine columns from two tables.
Union Operator
Union is a great way to give a unique results set from different queries. A Union specifies that multiple result sets are to be combined and returned as a single result set.
Let’s look at an example below.
SELECT sh.orderdate, sh.shipdate, sc.CustomerID,p.FirstName,p.LastName, st.Name as TerritoryNAme FROM [Sales].[SalesOrderHeaderEnlarged] sh INNER JOIN [Sales].[SalesTerritory] st on st.TerritoryID = sh.TerritoryID INNER JOIN [Sales].[Customer] sc on sh.CustomerID = sc.CustomerID INNER JOIN [Person].[Person] p on sh.CustomerID = p.BusinessEntityID WHERE sh.OrderDate between '07.01.2009' and '08.01.2009' UNION SELECT sh.orderdate, sh.shipdate, sc.CustomerID,p.FirstName,p.LastName, st.Name as TerritoryNAme FROM [Sales].[SalesOrderHeaderEnlarged] sh INNER JOIN [Sales].[SalesTerritory] st on st.TerritoryID = sh.TerritoryID INNER JOIN [Sales].[Customer] sc on sh.CustomerID = sc.CustomerID INNER JOIN [Person].[Person] p on sh.CustomerID = p.BusinessEntityID WHERE sh.ShipDate between '08.01.2009' and '09.01.2009'
This query gives us the distinct results of two separate queries. That’s nice in thought, but we’re making the database work too hard. The only difference between the two queries is that one query is searching a range on order date, and the other is ship date. Each table is called twice. The execution plan below shows the work this query is doing.
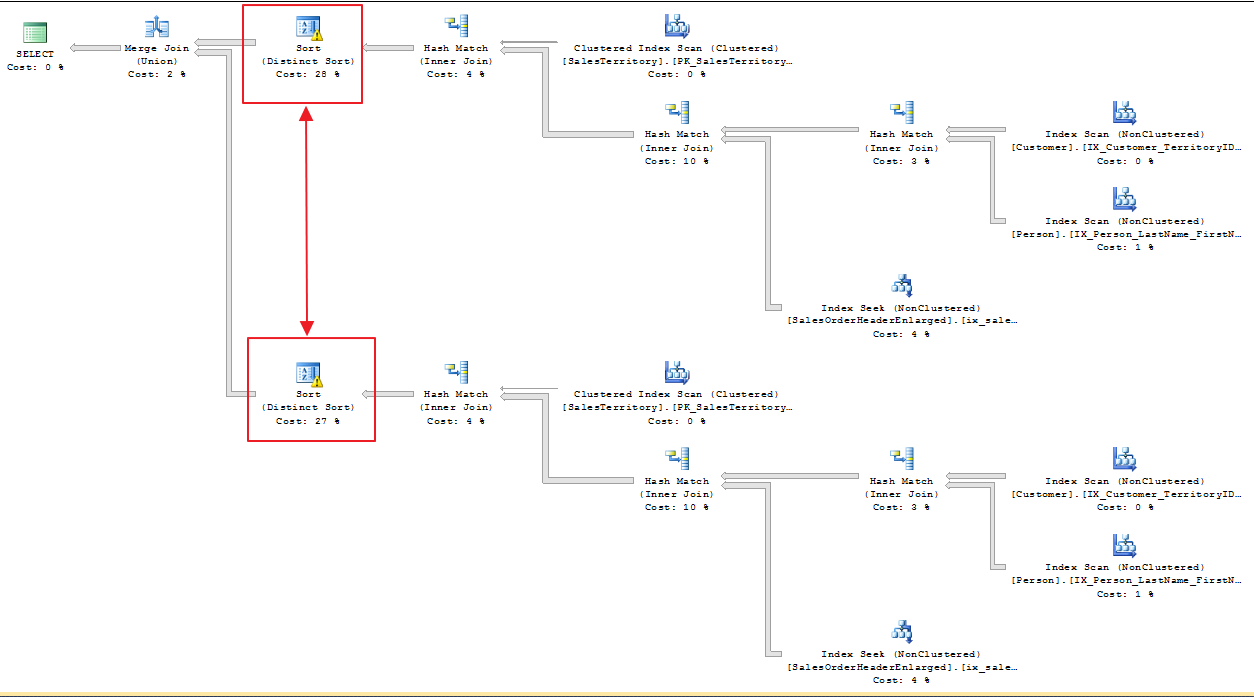
Notice how there are two scans on customer, two scans on person, two scans on SalesTerritory. There are two separate seeks on the indexes that are used for the where clause predicates.
The majority of the cost is used in the Sort of the execution plan. This is where this query is doing the work, and doing so in tempdb. In order for SQL Server to deliver one distinct recordset, it must use TEMPDB to sort each recordset, make sure that it is unique and join the two together.
We’ve accomplished a goal for a distinct recordset from two queries, but scalability will come into question. Let’s take a look at the statistics IO for this query below.
/*********************************************** ** BEGIN UNION ************************************************/ (95667 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeaderEnlarged'. Scan count 2, logical reads 1142, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Person'. Scan count 2, logical reads 216, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customer'. Scan count 2, logical reads 74, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesTerritory'. Scan count 2, logical reads 4, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 406 ms, elapsed time = 2136 ms. /********************************************** ** END UNION ***********************************************/
All 4 tables in the query are scanned twice. This will increase with the number of unions used. The more this query is called, the more it will be noticed.
Union All
So, how do we mitigate the costs of a Union. Remember what the biggest cost of the execution plan is? The sort(distinct) and merge. One way to mitigate this is the union all. The benefits of the union all are that it does not create a distinct union of the recordsets. Let’s examine the query below.
SELECT sh.orderdate, sh.shipdate, sc.CustomerID,p.FirstName,p.LastName, st.Name as TerritoryNAme FROM [Sales].[SalesOrderHeaderEnlarged] sh INNER JOIN [Sales].[SalesTerritory] st on st.TerritoryID = sh.TerritoryID INNER JOIN [Sales].[Customer] sc on sh.CustomerID = sc.CustomerID INNER JOIN [Person].[Person] p on sh.CustomerID = p.BusinessEntityID WHERE sh.OrderDate between '07.01.2009' and '08.01.2009' UNION ALL SELECT sh.orderdate, sh.shipdate, sc.CustomerID,p.FirstName,p.LastName, st.Name as TerritoryNAme FROM [Sales].[SalesOrderHeaderEnlarged] sh INNER JOIN [Sales].[SalesTerritory] st on st.TerritoryID = sh.TerritoryID INNER JOIN [Sales].[Customer] sc on sh.CustomerID = sc.CustomerID INNER JOIN [Person].[Person] p on sh.CustomerID = p.BusinessEntityID WHERE sh.ShipDate between '08.01.2009' and '09.01.2009'
The only difference between the two queries is the “ALL” keyword. Let’s take a look at the execution plan.
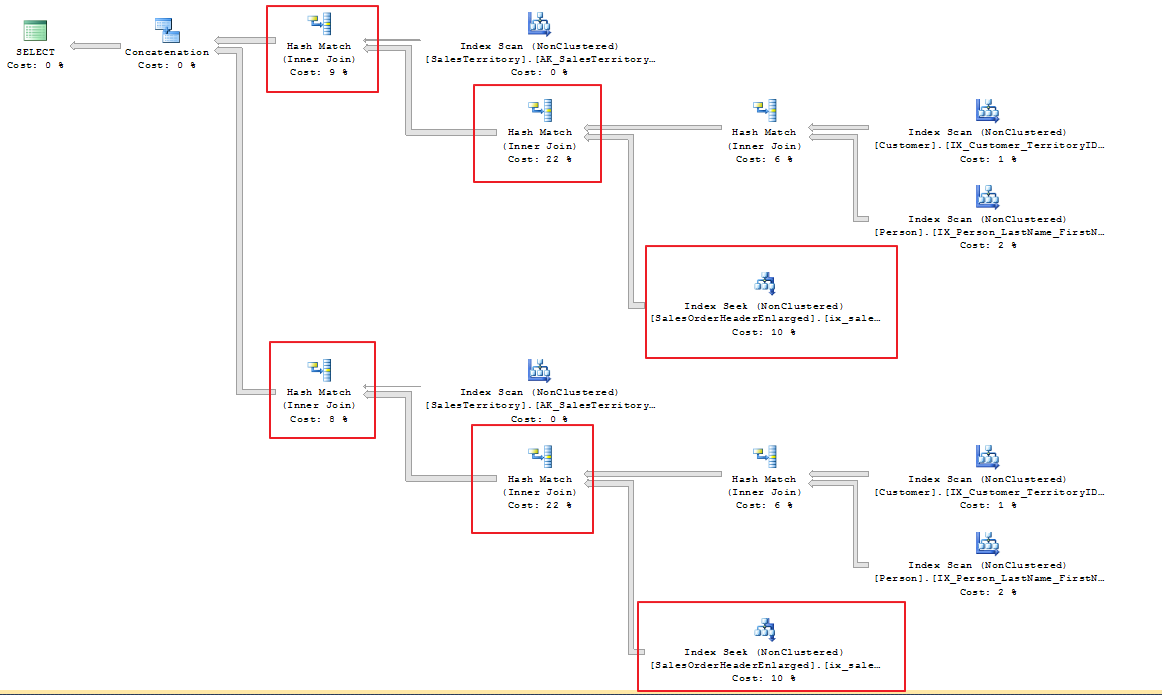
Now there is no sort(distinct) in the execution plan. There is no merge. We still have the two sets of scans against all of the tables, as shown in the execution plan and statistics IO below. The query did run about 800ms faster. Focus on the CPU time. The CPU time of this query is about 12% of the UNION query.
There is a problem however, we have more records in our recordset. We will address that later.
/*************************************************** ** BEGIN UNION ALL ***************************************************/ (123702 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeaderEnlarged'. Scan count 2, logical reads 1142, physical reads 2, read-ahead reads 1137, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Person'. Scan count 2, logical reads 216, physical reads 1, read-ahead reads 106, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customer'. Scan count 2, logical reads 74, physical reads 1, read-ahead reads 35, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesTerritory'. Scan count 2, logical reads 4, physical reads 1, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 47 ms, elapsed time = 1704 ms. /*************************************************** ** BEGIN UNION ALL ***************************************************/
Using “OR”
So, we’ve shown that the union all performs much better than the union, but we still have multiple scans. In the query example that we have shown, the only difference is in the where clause. We are searching against the same tables, but two different date ranges on two different columns.
I’ve seen this many times, this can be simply altered by using an “or”(sparingly). Let’s see the query below.
SELECT sh.orderdate, sh.shipdate, sc.CustomerID,p.FirstName,p.LastName, st.Name as TerritoryNAme FROM [Sales].[SalesOrderHeaderEnlarged] sh INNER JOIN [Sales].[SalesTerritory] st on st.TerritoryID = sh.TerritoryID INNER JOIN [Sales].[Customer] sc on sh.CustomerID = sc.CustomerID INNER JOIN [Person].[Person] p on sh.CustomerID = p.BusinessEntityID WHERE sh.OrderDate between '07.01.2009' and '08.01.2009' OR sh.ShipDate between '08.01.2009' and '09.01.2009'
We are querying each table only once. This is also shown in the execution plan as follows.
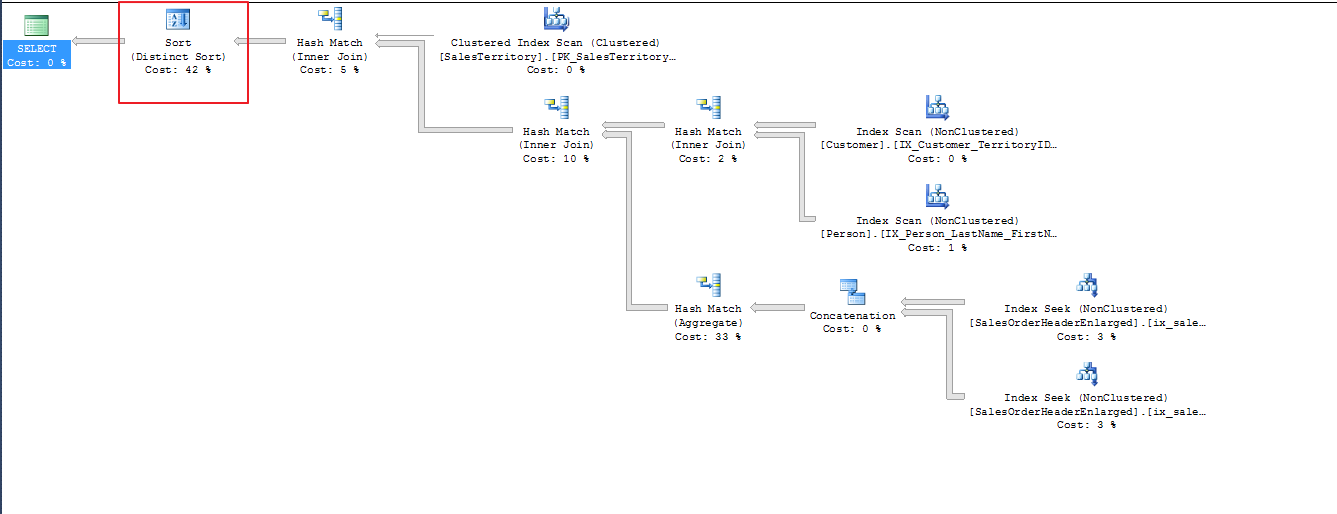
The execution plan is much more simple. We are performing index scans on customer and person, and index seeks on indexes for SalesOrderHeaderEnlarged on the OrderDate and ShipDate columns. Along with the execution plan, let’s take a look at the statistics IO.
/*************************************************** ** BEGIN "OR" ***************************************************/ (108090 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeaderEnlarged'. Scan count 2, logical reads 1142, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Person'. Scan count 1, logical reads 108, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customer'. Scan count 1, logical reads 37, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesTerritory'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 421 ms, elapsed time = 1708 ms. /*************************************************** ** END "OR" ***************************************************/
Person, Customer, and SalesTerritory all are scanned only once. Our total logical reads are going to go from about 2872 reads to 2431. We are saving 441 reads against the database. The CPU time of the “or” is roughly the same as the UNION, but the elapsed time is about 800ms less. Does this solve our problem? No. We still have too many records. Let’s see how we solve this.
The distinct “OR”
So, the “or” clause does decrease our overall reads and elapsed time, but we do still have too many records. In this case, we will need to make use of tempdb and use “distinct”. We need to use distinct sparingly, but in this case, it is necessary. The expected results count are 95667, but through our “or” and union all, we have seen repeated results in our recordset. As we show below, we will add distinct to the select clause. This will return a recordset with no repeating records.
SELECT distinct sh.orderdate, sh.shipdate, sc.CustomerID,p.FirstName,p.LastName, st.Name as TerritoryNAme FROM [Sales].[SalesOrderHeaderEnlarged] sh INNER JOIN [Sales].[SalesTerritory] st on st.TerritoryID = sh.TerritoryID INNER JOIN [Sales].[Customer] sc on sh.CustomerID = sc.CustomerID INNER JOIN [Person].[Person] p on sh.CustomerID = p.BusinessEntityID WHERE sh.OrderDate between '07.01.2009' and '08.01.2009' OR sh.ShipDate between '08.01.2009' and '09.01.2009'
Let’s examine execution plan for this change. We see now that 42% of the cost comes from the distinct sort. The plan is the same as “or” with the addition of the distinct sort.
Let’s review the statistics IO. As shown below, we DO receive the desired amount of records. Unfortunately, our CPU cost has risen. Our reads are still lower than the union and our elapsed execution time is still 800ms less than the union all.
/*************************************************** ** BEGIN "distinct OR" ***************************************************/ (95667 row(s) affected) Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesOrderHeaderEnlarged'. Scan count 2, logical reads 1142, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Person'. Scan count 1, logical reads 108, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Customer'. Scan count 1, logical reads 37, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'SalesTerritory'. Scan count 1, logical reads 2, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 686 ms, elapsed time = 1857 ms. /*************************************************** ** END "distinct OR" ***************************************************/
Conclusion
The union operator has its uses, but we can see that those uses come at a cost of reads and tempdb usage. At times, we may not have an alternative, but we need to be aware of the costs and use this functionality accordingly.
Up next: Taking advantage of Sargability