Statistics and PowerBI Visualizations, Part One
Statistics and PowerBI Visualizations, Part One
In an effort to teach myself PowerBI, I thought that I could learn PowerBI while working with something that I know. While in New York City, I was discussing this topic with the incomparable Patrick LeBlanc(b|t). In the end, we decided that we would do a session together where he would show statistics and I would show PowerBI. We were able to present this at Summit 2017. I will review my experience at Summit 2017 in another blog.
In this article, we are going to discuss how SQL Server uses statistics. Differences between how 2016 and older versions use statistics for the optimizer. In the end, we will review the report that Mr. LeBlanc designed. To make a note, some of the examples were provided by Mr. Chris Bell(b|t).
What Are Statistics?
Statistics are the information regarding the distribution of values in column(s) or a table or index. SQL Server uses the Cardinality(Selectivity) of statistics to estimate the number of records that are returned. This helps SQL Server Query Optimizer determine a proper execution plan.
Statistics can be created in several ways. They are created automatically when querying a column or columns. They are created when creating an index; they can be explicitly created and can even be filtered. Statistics can be created on multiple columns, but when statistics are created automatically, it will be on one column.
Let’s look below to show that statistics do not exist on a column until it is queried or they are manually created. In the code below, you will see that I have a “drop statistics” call commented out. You may have to drop statistics on whatever column you are testing this with. Not on production of course.
USE AdventureWorks2012;
GO
-- drop statistics sales.SalesOrderDetail._WA_Sys_00000007_44CA3770
/*****************************************************************************************
** Note No stats - column not referenced before now.
*****************************************************************************************/
declare @object_name varchar(256) = 'Sales.SalesOrderDetail' ,
@StatName varchar(256) = 'UnitPrice'
DBCC SHOW_STATISTICS(@object_name, @StatName) WITH STAT_HEADER ;
DBCC SHOW_STATISTICS(@object_name, @StatName) WITH DENSITY_VECTOR ;
DBCC SHOW_STATISTICS(@object_name, @StatName) WITH HISTOGRAM ;
What you will see is actually an error. This is because statistics do not exists.
Msg 2767, Level 16, State 1, Line 17 Could not locate statistics 'UnitPrice' in the system catalogs. DBCC execution completed. If DBCC printed error messages, contact your system administrator. Msg 2767, Level 16, State 1, Line 19 Could not locate statistics 'UnitPrice' in the system catalogs. DBCC execution completed. If DBCC printed error messages, contact your system administrator. Msg 2767, Level 16, State 1, Line 21 Could not locate statistics 'UnitPrice' in the system catalogs. DBCC execution completed. If DBCC printed error messages, contact your system administrator.
Now, let’s query the column.
/****************************************************************************
** Query table with where on unitprice
****************************************************************************/
select *
from sales.SalesOrderDetail
where UnitPrice > 1000
When we run the statistics, we shall see that statistics now exist on the column.
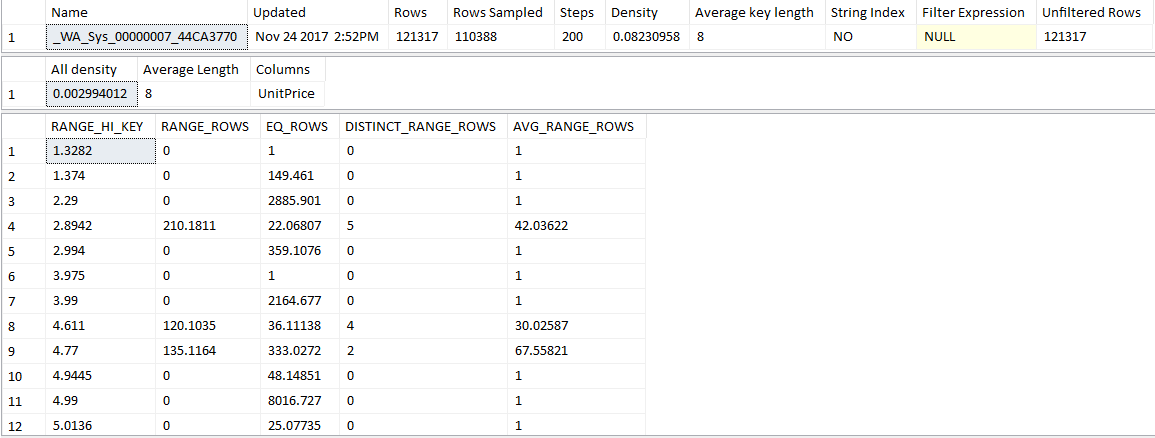
DBCC SHOW_STATISTICS
So what does all of that information above show us? First, let’s examine how it is called. The arguments for the call are the <table_or_indexed_view_name> and the <target>. The <target> is the column name, index name or statistics name.
You can run this without any options and will have 3 results sets returned. The STAT_HEADER, DENSITY_VECTOR, HISTOGRAM. Personally, I prefer to run them separately. This way I can see each result separately.
STAT_HEADER
This is paraphrased from Microsoft.
declare @object_name varchar(256) = 'Sales.SalesOrderDetail' ,
@StatName varchar(256) = 'UnitPrice'
DBCC SHOW_STATISTICS(@object_name, @StatName) WITH STAT_HEADER ;
| Column Name | Description |
|---|---|
| Name | Name of the Stat/index |
| Updated | Last time the Statistics were updated |
| Rows | Total number of rows in the Table/Indexed view the last time stats were updated |
| Rows Sampled | Number of rows sampled for the stats calculation. If Rows Sampled is less than Rows, the Histogram and Density results are based on a sample of rows |
| Steps | The number of steps/groupings in the Histogram. Regardless the size of the table, the maximum number of steps is 200 |
| Density | Displayed only for backward compatibility with versions before SQL Server 2008 |
| Average Key Length | Average Bytes per value of all the key columns |
| String Index | “Yes” means that the statistics object contains string summary such as “Where ProductName like ‘%Bike'” |
| Filter Expression | Predication for the filtered index/statistic. NULL means non-filtered |
| Unfiltered Rows | Total number of rows in the table before applying the filter expression |
| Persisted Sample Percent | Persisted sample percentage used for statistic updates that do not explicitly specify a sampling percentage. If value is zero, then no persisted sample percentage is set for this statistic.
Applies to: SQL Server 2016 SP1 CU4 |
DENSITY_VECTOR
The density vector is when the query optimizer uses densities to raise the selectivity(cardinality) estimates for queries that return multiple columns for the same table/indexed view. One density per each prefix of columns in the object.
declare @object_name varchar(256) = 'Sales.SalesOrderDetail' ,
@StatName varchar(256) = 'UnitPrice'
DBCC SHOW_STATISTICS(@object_name, @StatName) WITH DENSITY_VECTOR ;
| Column Name | Description |
|---|---|
| All Density | Density is 1 / distinct values. Results display density for each prefix of columns in the statistics object, one row per density. A distinct value is a distinct list of the column values per row and per columns prefix |
| Average Length | Average length, in bytes, to store a list of the column values for the column prefix. |
| Columns | Names of the columns in the prefix |
HISTOGRAM
This is the fun one. This explains what statistics the optimizer uses to create the best execution plan that it can.
declare @object_name varchar(256) = 'Sales.SalesOrderDetail' ,
@StatName varchar(256) = 'UnitPrice'
DBCC SHOW_STATISTICS(@object_name, @StatName) WITH HISTOGRAM ;
| Column Name | Description |
|---|---|
| Range_HI_Key | This is the upper bound value for the histogram step. The step/grouping contains values sorted above the previous Range_HI_Key to the current. |
| Range_Rows | This is the estimated count of the rows in the step, EXCLUDING the Range_HI_Key |
| EQ_Rows | This is the estimated number of rows for columns who have the value of the Range_HI_Key |
| Distinct_Range_Rows | This is the estimated DISTINCT count of the rows in the step, EXCLUDING the Range_HI_Key |
| Avg_Range_Rows | Average number of records, with duplicate values within the step, excluding the Range_HI_Key – (RANGE_ROWS / DISTINCT_RANGE_ROWS for DISTINCT_RANGE_ROWS > 0). |
Now that all the details are “out of the way”, in the next post, we’ll show how SQL Server uses all of this fun information. Statistics and PowerBI Visualizations, Part Two coming shortly.